
This powerful feature in the FileHold Desktop Client requires you to have basic to intermediate knowledge of Microsoft SQL Server and is explained in this help article. Your database administrator may be required to help with this step.
Document scanning project case study
In this project, an organization’s Human Resources department had thousands of paper files for thousands of employees. Each had to be scanned and imported into FileHold for long term storage, management, updating and lookup. All scanning projects benefit from automation so that scanner operators work productively.
SmartSoft Capture was setup for this project to scan an entire employee HR package that is scanned as a single batch of documents. Individual forms and documents in the batch are automatically separated so that individual PDF’s are managed inside of FileHold’s library.
For each document in the batch of documents for a single index field for Social Security Number (SSN) is captured at scan time from the document via zonal OCR. SmartSoft Capture has the ability to provide manual text entry fields, or perform zonal OCR on specific regions on a form, or read barcode information.
In the database lookup tab in the Manage import settings, the import can use the schema’s database lookup settings or configure another database to use.
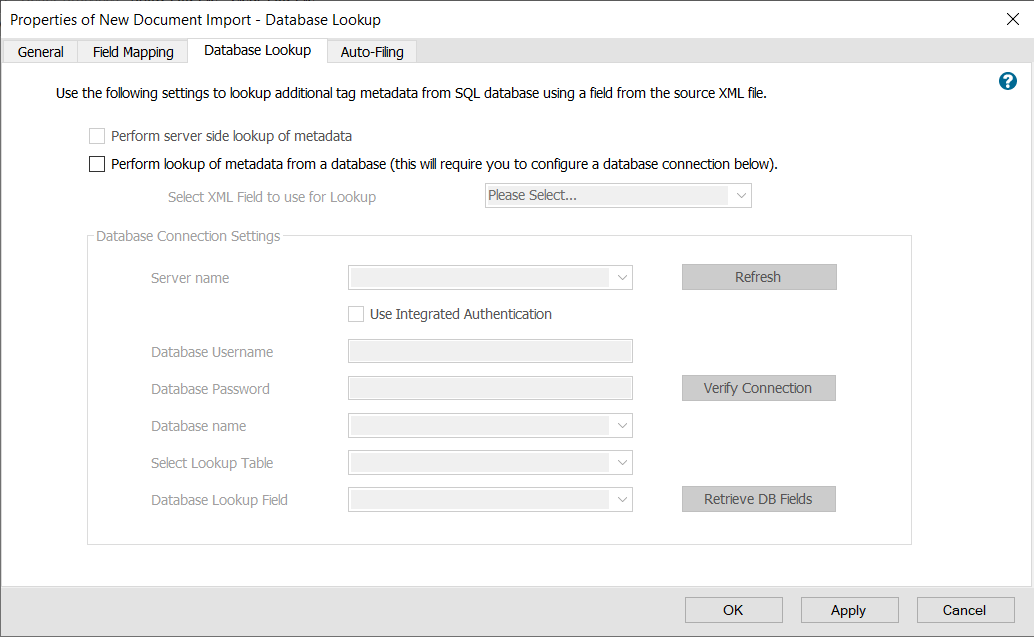
In the scanning software, such as SmartSoft Capture, the software autmatically sets the type of HR form and the SSN field. Both values are then written for each document to an XML file that is then processed by the FileHold Desktop Client manage import engine.
In the Manage imports tool, the fields are mapped from the xml file to the corresponding metadata fields in FileHold for the “personnel file” document type.
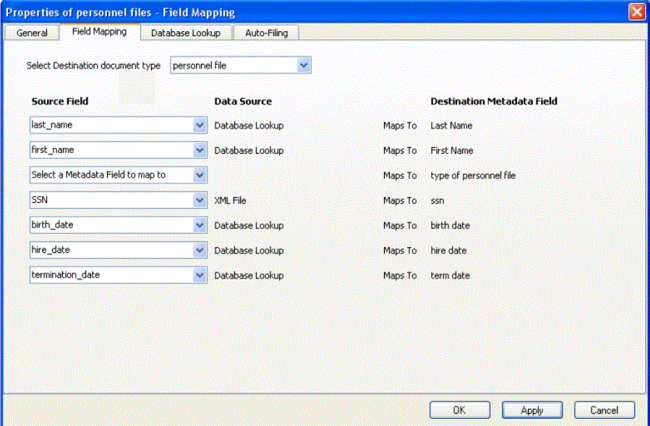
Based on SSN # and the lookup from the Database, FileHold can then retrieve and automatically fill in all the corresponding fields for each scanned image. Then FileHold import engine reads the SSN and does the DB Lookup and then auto fills in all the other fields.
The metadata fields in the metadata pane for the HR file have all been automatically filled based on the SSN value and subsequent database lookup from the payroll Microsoft SQL Server database where all the human resources data resides. Some fields have been redacted to maintain privacy.
