
Automatically Extracting Metadata Values from Content Controls in Microsoft Word Documents (e-Forms) in FileHold 12
In FileHold 12, you can now create a “XML Node Extraction Rule” for a Microsoft Word document (or e-Form) that has content controls. After the document has been properly configured, the values in the content controls can be extracted into the metadata fields when the e-Form is added to FileHold.
Using Microsoft Word 2007 or higher, you can create forms using the content controls available in Microsoft Word developer mode. FileHold will be offering form creation as a professional service for a charge when FileHold 12 is released.
Once a Word form has been created, the XML nodes mapped, and the extraction rule in FileHold added, the form can be used as a template available for download in FileHold. Users will get a copy of the form, fill out the form, save the form as a new file and add it to FileHold. When the form is added to FileHold, the mapped fields on the form will be automatically extracted to the metadata fields.
Creating e-forms
E-forms are created using an “XML Node Extraction Rule” for a Microsoft Word document that has content controls. After the document has been properly configured, the values in the content controls can be extracted into the metadata fields of the document management software.
In the example below, an invoice e-Form was created using content controls such as text fields, date pickers, and drop down lists found in the Developer ribbon of Microsoft Word.

After some additional configuration to the Invoice e-Form (which will be explained later in this article) the content control values will be extracted from the form and into the metadata fields of the schema. In the example below, the values in the content controls of the Pet Store Supply Invoice was automatically extracted into the metadata fields of the “Pet Store Supply – Invoice” schema in the document management software.

Extracting e-forms Content into the Document Management System
The process for extracting Microsoft Word content control values in the e-Form into the metadata fields of the document management software is shown below. In the first step, the e-Form containing content controls needs to be created in Microsoft Word.

As previously mentioned, the Microsoft Word e-Form will require some additional configuration before the values from the content controls can be extracted. After the e-Form is created, the second step is to use the Word 2007 Content Control Toolkit to map the content controls in the e-Form to the custom XML nodes created in the toolkit. The free toolkit is made by Microsoft, is actively supported and available for download here: http://dbe.codeplex.com/.
The Content Control Toolkit has been archived by Microsoft. To install, follow these instructions: https://social.msdn.microsoft.com/Forums/en-US/bb33d060-49a6-407d-a003-6609727b8be8/codeplex-archive-files-how-to-use-them
In the toolkit, a XML code is written that contains the “XML nodes” that will be mapped to the content controls on the e-form and assigned a unique namespace. The XML nodes define which content control values will be extracted to the metadata fields from the e-Form. The unique namespace is required in order to create the unique extraction rule in the document management software. In the example below, it shows the XML code with the unique namespace defined.

After creating the XML nodes in the XML code, the XML nodes are dragged and dropped to the content controls to bind the content together. Once they are bound, the document is saved and used to create the extraction rule in the document management software. The example below shows how to bind the XML nodes to the content controls in the Content Control Toolkit.

The next step is to create the XML Node Extraction Rule in the document management software. When creating the rule, you will need to select the mapped Microsoft Word e-Form document as the template to create the rule from. The unique namespace that was given to the document in the Content Control Kit will allow the extraction rule to recognize that the values in that document can be extracted. Having a unique namespace allows you to create as many XML Node extraction rules for as many documents that you like as long as the namespace for each document is unique.
In the example below, a specific schema called “Pet Store Supply – Invoice” was created to contain the metadata fields that will be extracted from the e-Form. When creating the XML Node extraction rule, you map the metadata field names in the schema to the “XML nodes” created in the Content Control Kit. Notice that the unique namespace is displayed in the Select XML Node window.
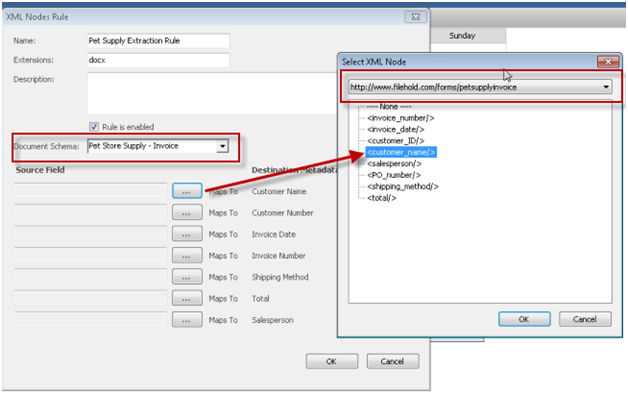
Once the XML Node Extraction Rule has been created, it will be shown in the List of Extraction Rules.
In the last step, a Library Administrator can add the mapped Microsoft Word e-Form to the document management system. Any user with publishing rights or greater can get a copy of the e-Form document and fill it out. They can then save the e-Form and add it to the document management software using the schema that uses the extraction rule. The metadata field values will be automatically extracted from the content controls on the e-Form.
FileHold document management software offers the creation of Microsoft Word based e-Forms with content controls as a professional service. Please contact with any inquires.